Snippet: Find duplicate files on linux
Once in a while a client comes by and asks for help with their duplicate files on the cloud storage platform. This happens especially often, when users manage their backups on their own without proper introduction or training. Then you’ll face files over files, scattered everywhere on the client’s storage, with uncertain timestamps and no meaningful user logs. That’s when the following shell script might come in handy.
The following command will find two or more identical files in the current location recursively, and returns them in an ordered manner.
Two files shall be considered identical when they have:
- same file name
- same file size
- same md5 checksum
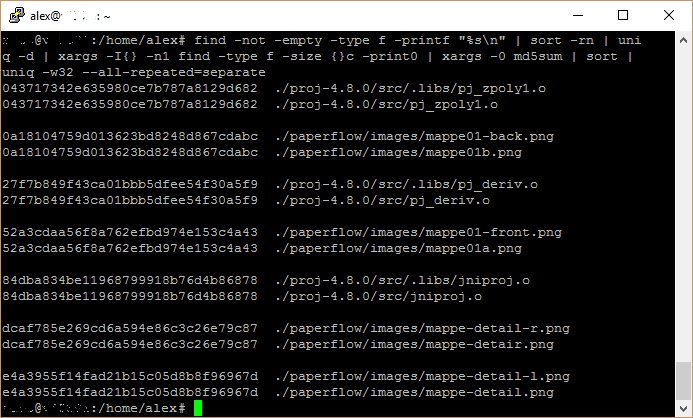
find -not -empty -type f -printf "%s\n" | sort -rn | uniq -d | xargs -I{} -n1 find -type f -size {}c -print0 | xargs -0 md5sum | sort | uniq -w32 --all-repeated=separate
Let’s take a look into that command chain.
find -not -empty -type f -printf "%s\n" Find any non empty files and print their file sizes unordered.
| sort -rn Sort the file sizes descending.
| uniq -d Filter only duplicate file sizes.
| xargs -I{} -n1 find -type f -size {}c -print0 Find file which match the file sizes.
| xargs -0 md5sum Create md5 checksum for each file.
| sort Sort the results as "CHECKSUM FILE".
| uniq -w32 --all-repeated=separate Add newlines between the sets of duplicates.
And here it is.